Probabilistic latent semantic analysis
Probabilistic latent semantic analysis (PLSA), also known as probabilistic latent semantic indexing (PLSI, especially in information retrieval circles) is a statistical technique for the analysis of two-mode and co-occurrence data. PLSA evolved from latent semantic analysis, adding a sounder probabilistic model. PLSA has applications in information retrieval and filtering, natural language processing, machine learning from text, and related areas. It was introduced in 1999 by Jan Puzicha and Thomas Hofmann,[1] and it is related [2] to non-negative matrix factorization.
Compared to standard latent semantic analysis which stems from linear algebra and downsizes the occurrence tables (usually via a singular value decomposition), probabilistic latent semantic analysis is based on a mixture decomposition derived from a latent class model. This results in a more principled approach which has a solid foundation in statistics.
Considering observations in the form of co-occurrences 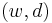 of words and documents, PLSA models the probability of each co-occurrence as a mixture of conditionally independent multinomial distributions:
of words and documents, PLSA models the probability of each co-occurrence as a mixture of conditionally independent multinomial distributions:
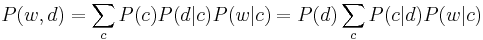
The first formulation is the symmetric formulation, where 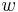 and
and 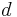 are both generated from the latent class
are both generated from the latent class 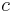 in similar ways (using the conditional probabilities
in similar ways (using the conditional probabilities 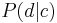 and
and 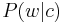 ), whereas the second formulation is the asymmetric formulation, where, for each document , a latent class is chosen conditionally to the document according to
), whereas the second formulation is the asymmetric formulation, where, for each document , a latent class is chosen conditionally to the document according to 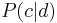 , and a word is then generated from that class according to . Although we have used words and documents in this example, the co-occurrence of any couple of discrete variables may be modelled in exactly the same way.
, and a word is then generated from that class according to . Although we have used words and documents in this example, the co-occurrence of any couple of discrete variables may be modelled in exactly the same way.
It is reported that the aspect model used in the probabilistic latent semantic analysis has severe overfitting problems.[3] The number of parameters grows linearly with the number of documents. In addition, although PLSA is a generative model of the documents in the collection it is estimated on, it is not a generative model of new documents.
PLSA may be used in a discriminative setting, via Fisher kernels.[4]
Contents |
Evolutions of PLSA
- Hierarchical extensions:
- Generative models: The following models have been developed to address an often-criticized shortcoming of PLSA, namely that it is not a proper generative model for new documents.
- Latent Dirichlet allocation - adds a Dirichlet prior on the per-document topic distribution
- Higher-order data: Although this is rarely discussed in the scientific literature, PLSA extends naturally to higher order data (three modes and higher), i.e. it can model co-occurrences over three or more variables. In the symmetric formulation above, this is done simply by adding conditional probability distributions for these additional variables. This is the probabilistic analogue to non-negative tensor factorisation.
References and notes
- ^ Thomas Hofmann, Probabilistic Latent Semantic Indexing, Proceedings of the Twenty-Second Annual International SIGIR Conference on Research and Development in Information Retrieval (SIGIR-99), 1999
- ^ Chris Ding, Tao Li, Wei Peng (2006). "[http://www.aaai.org/Papers/AAAI/2006/AAAI06-055.pdf Nonnegative Matrix Factorization and Probabilistic Latent Semantic Indexing: Equivalence Chi-Square Statistic, and a Hybrid Method. AAAI 2006 ]
- ^ Blei, David M.; Andrew Y. Ng, Michael I. Jordan (2003). "Latent Dirichlet Allocation". Journal of Machine Learning Research 3: 993–1022. doi:10.1162/jmlr.2003.3.4-5.993. http://jmlr.csail.mit.edu/papers/volume3/blei03a/blei03a.pdf.
- ^ Thomas Hofmann, Learning the Similarity of Documents : an information-geometric approach to document retrieval and categorization, Advances in Neural Information Processing Systems 12, pp-914-920, MIT Press, 2000
- ^ Alexei Vinokourov and Mark Girolami, A Probabilistic Framework for the Hierarchic Organisation and Classification of Document Collections, in Information Processing and Management, 2002
- ^ Eric Gaussier, Cyril Goutte, Kris Popat and Francine Chen, A Hierarchical Model for Clustering and Categorising Documents, in "Advances in Information Retrieval -- Proceedings of the 24th BCS-IRSG European Colloquium on IR Research (ECIR-02)", 2002
See also
- Compound term processing
- Latent Dirichlet allocation
- Latent semantic analysis
- Pachinko allocation
- Vector space model